[案例] 文章采集:使用AI马驹(浏览器插件)实现必应搜索结果的收集【AI浏览器】
人工智能+ :必应搜索结果的自动化
基于数码文章自动化下载脚本修改为必应搜索结果自动化获取
提示词
将此nodejs文件,修改为必应搜索结果的整合。
const fs = require('fs').promises;
const path = require('path');
// API配置
const API_BASE = 'http://browser.bb53m4hk65am1ogwky0n.html.dtns.top/api';
const SEARCH_URL = 'https://www.bing.com/search?q='; // 基础搜索URL,可自定义查询词
// 辅助函数:延迟
const sleep = (ms) => new Promise(resolve => setTimeout(resolve, ms));
// 获取当前日期字符串 YYYY-MM-DD
const getTodayStr = () => {
const now = new Date();
return `${now.getFullYear()}-${String(now.getMonth() + 1).padStart(2, '0')}-${String(now.getDate()).padStart(2, '0')}`;
};
// 获取当前时间字符串 HH-MM-SS
const getTimeStr = () => {
const now = new Date();
return `${String(now.getHours()).padStart(2, '0')}-${String(now.getMinutes()).padStart(2, '0')}-${String(now.getSeconds()).padStart(2, '0')}`;
};
// 判断是否为必应搜索结果链接(过滤掉必应自身的链接)
const isSearchResultLink = (href) => {
if (!href) return false;
// 排除必应自身的链接、空链接、javascript链接等
const excludePatterns = [
/^https?:\/\/(www\.)?bing\.com\//,
/^https?:\/\/[^/]*\.bing\.com\//,
/^javascript:/,
/^#/,
/^\/search/,
/^\/images/,
/^\/videos/,
/^\/news/,
/^\/maps/
];
// 如果有排除模式匹配,则不是搜索结果链接
for (const pattern of excludePatterns) {
if (pattern.test(href)) {
return false;
}
}
// 有效的HTTP/HTTPS链接
return href.startsWith('http://') || href.startsWith('https://');
};
// 调用API打开标签页
const openTab = async (url) => {
const apiUrl = `${API_BASE}/tabs/open?url=${encodeURIComponent(url)}`;
const response = await fetch(apiUrl);
if (!response.ok) {
throw new Error(`打开标签页失败: ${response.statusText}`);
}
const data = await response.json();
console.log(`✓ 已打开: ${url.substring(0, 80)}...`);
return data;
};
// 获取页面所有链接
const fetchPageLinks = async () => {
const apiUrl = `${API_BASE}/page/links`;
const response = await fetch(apiUrl);
if (!response.ok) {
throw new Error(`获取链接失败: ${response.statusText}`);
}
const data = await response.json();
if (!data.success) {
throw new Error(`获取链接API返回错误: ${JSON.stringify(data)}`);
}
return data.links || [];
};
// 获取页面标题
const fetchPageTitle = async () => {
const apiUrl = `${API_BASE}/page/title`;
const response = await fetch(apiUrl);
if (!response.ok) {
throw new Error(`获取标题失败: ${response.statusText}`);
}
const data = await response.json();
if (!data.success) {
return '';
}
return data.title || '';
};
// 获取页面纯文本内容
const fetchPageText = async () => {
const apiUrl = `${API_BASE}/page/visible-text/merged`;
const response = await fetch(apiUrl);
if (!response.ok) {
throw new Error(`获取文本失败: ${response.statusText}`);
}
const data = await response.json();
if (!data.success) {
throw new Error(`获取文本API返回错误: ${JSON.stringify(data)}`);
}
return data.text || '';
};
// 保存搜索结果列表JSON
const saveSearchResultsJson = async (results, searchQuery, today, timeStr) => {
const dataDir = path.join(process.cwd(), 'bing_search_results');
await fs.mkdir(dataDir, { recursive: true });
const filename = `Bing搜索_${searchQuery}_${today}_${timeStr}.json`;
const filepath = path.join(dataDir, filename);
await fs.writeFile(filepath, JSON.stringify({
searchQuery: searchQuery,
searchTime: new Date().toISOString(),
totalResults: results.length,
results: results
}, null, 2), 'utf-8');
console.log(`✓ 已保存搜索结果列表: ${filepath}`);
return filepath;
};
// 保存单个搜索结果为Markdown
const saveResultMarkdown = async (result, searchQuery, today) => {
const { title, url, content, snippet } = result;
const safeSearchQuery = searchQuery.replace(/[\\/:*?"<>|]/g, '_').substring(0, 30);
const resultDir = path.join(process.cwd(), 'bing_search_results', safeSearchQuery, today);
await fs.mkdir(resultDir, { recursive: true });
// 从URL中提取域名作为文件名的一部分
let domain = '';
try {
const urlObj = new URL(url);
domain = urlObj.hostname.replace(/^www\./, '');
} catch(e) {
domain = 'unknown';
}
const safeTitle = title.replace(/[\\/:*?"<>|]/g, '_').substring(0, 50);
const timestamp = Date.now();
const filename = `${timestamp}_${domain}_${safeTitle}.md`;
const filepath = path.join(resultDir, filename);
// 构建Markdown内容
const markdown = `# ${title}\n\n> 原文链接:${url}\n> 搜索结果摘要:${snippet || '无摘要'}\n\n---\n\n## 页面内容\n\n${content || '无法获取页面内容'}\n\n---\n\n*本文由必应搜索采集工具生成* \n*搜索关键词:${searchQuery}* \n*采集时间:${new Date().toLocaleString()}*\n`;
await fs.writeFile(filepath, markdown, 'utf-8');
console.log(`✓ 已保存结果: ${filename}`);
return filepath;
};
// 解析搜索结果页面,提取搜索结果项
const parseSearchResults = (links, pageTitle) => {
const results = [];
const seenUrls = new Set(); // 去重
// 必应搜索结果的链接通常包含在带有特定属性的元素中
// 但这里我们通过API获取所有链接,需要智能识别哪些是真正的搜索结果
for (const link of links) {
const href = link.href;
const text = link.text || '';
// 检查是否为有效的搜索结果链接
if (!isSearchResultLink(href)) continue;
// 去重
if (seenUrls.has(href)) continue;
seenUrls.add(href);
// 提取标题(优先使用链接文本,如果没有则从URL推断)
let title = text.trim();
if (!title || title.length < 5) {
// 如果链接文本太短,尝试从URL获取更好的标题
try {
const urlObj = new URL(href);
title = urlObj.hostname.replace(/^www\./, '') + urlObj.pathname;
} catch(e) {
title = href;
}
}
// 清理标题中的多余空白和特殊字符
title = title.replace(/\n/g, ' ').replace(/\s+/g, ' ').trim();
// 跳过过短的标题
if (title.length < 3) continue;
results.push({
title: title,
url: href,
snippet: '', // 必应搜索结果摘要可能需要额外解析,这里留空或从链接文本中提取
visible: link.visible,
collectedAt: new Date().toISOString()
});
}
return results;
};
// 命令行参数解析
const parseArguments = () => {
const args = process.argv.slice(2);
let searchQuery = '';
let maxResults = 10;
let fetchContent = true;
for (let i = 0; i < args.length; i++) {
if (args[i] === '--query' || args[i] === '-q') {
searchQuery = args[++i];
} else if (args[i] === '--max' || args[i] === '-m') {
maxResults = parseInt(args[++i]) || 10;
} else if (args[i] === '--no-content') {
fetchContent = false;
} else if (args[i] === '--help' || args[i] === '-h') {
console.log(`
使用方法: node bing-search.js [选项]
选项:
--query, -q 搜索关键词 (必需)
--max, -m 最大采集结果数 (默认: 10)
--no-content 只采集链接,不获取页面内容
--help, -h 显示帮助信息
示例:
node bing-search.js --query "Node.js教程"
node bing-search.js -q "人工智能" -m 20
node bing-search.js --query "天气预报" --no-content
`);
process.exit(0);
}
}
if (!searchQuery) {
console.error('错误: 请使用 --query 参数指定搜索关键词');
console.log('使用 --help 查看帮助');
process.exit(1);
}
return { searchQuery, maxResults, fetchContent };
};
// 主函数
async function main() {
console.log('=== 必应搜索结果采集工具 ===\n');
// 解析命令行参数
const { searchQuery, maxResults, fetchContent } = parseArguments();
const today = getTodayStr();
const timeStr = getTimeStr();
const searchUrl = SEARCH_URL + encodeURIComponent(searchQuery);
const results = [];
console.log(`搜索关键词: ${searchQuery}`);
console.log(`搜索URL: ${searchUrl}`);
console.log(`最大采集数: ${maxResults}`);
console.log(`获取页面内容: ${fetchContent ? '是' : '否'}\n`);
try {
// 1. 打开必应搜索页面
console.log(`步骤1: 打开搜索页面...`);
await openTab(searchUrl);
await sleep(4000); // 等待页面完全加载
// 2. 获取页面标题
// console.log(`\n步骤2: 获取页面信息...`);
// const pageTitle = await fetchPageTitle();
// console.log(`页面标题: ${pageTitle}`);
const pageTitle = '搜索的标题'
// 3. 获取页面所有链接
console.log(`\n步骤3: 获取页面链接...`);
const allLinks = await fetchPageLinks();
console.log(`共获取到 ${allLinks.length} 个链接`);
// 4. 解析搜索结果
console.log(`\n步骤4: 解析搜索结果...`);
const searchResults = parseSearchResults(allLinks, pageTitle);
console.log(`识别出搜索结果 ${searchResults.length} 个`);
if (searchResults.length === 0) {
console.log('未找到搜索结果,退出程序');
return;
}
// 限制结果数量
const limitedResults = searchResults.slice(0, maxResults);
console.log(`实际采集 ${limitedResults.length} 个结果`);
// 5. 显示搜索结果列表
console.log(`\n步骤5: 搜索结果列表预览:`);
limitedResults.forEach((result, idx) => {
console.log(` ${idx + 1}. ${result.title.substring(0, 60)}...`);
console.log(` ${result.url.substring(0, 80)}...`);
});
// 6. 保存搜索结果列表JSON
console.log(`\n步骤6: 保存搜索结果列表...`);
await saveSearchResultsJson(limitedResults, searchQuery, today, timeStr);
// 7. 如果需要,获取每个结果的详细内容
if (fetchContent) {
console.log(`\n步骤7: 采集搜索结果详细内容...`);
for (let i = 0; i < limitedResults.length; i++) {
const result = limitedResults[i];
console.log(`\n[${i + 1}/${limitedResults.length}] 处理: ${result.title.substring(0, 50)}...`);
try {
// 打开结果页面
await openTab(result.url);
await sleep(3500); // 等待页面加载
// 获取页面文本内容
const pageText = await fetchPageText();
// 保存Markdown文件
await saveResultMarkdown({
title: result.title,
url: result.url,
content: pageText,
snippet: result.snippet
}, searchQuery, today);
result.contentLength = pageText.length;
result.contentFetched = true;
// 避免请求过快
await sleep(800);
} catch (err) {
console.error(`✗ 处理失败: ${result.url.substring(0, 80)}`, err.message);
result.error = err.message;
result.contentFetched = false;
}
}
} else {
console.log(`\n步骤7: 跳过内容采集 (--no-content 模式)`);
}
// 8. 更新JSON文件(包含内容获取状态)
await saveSearchResultsJson(limitedResults, searchQuery, today, timeStr);
console.log('\n=== 采集完成 ===');
console.log(`- 搜索关键词: ${searchQuery}`);
console.log(`- 搜索结果数: ${limitedResults.length}`);
if (fetchContent) {
const successCount = limitedResults.filter(r => r.contentFetched).length;
console.log(`- 成功获取内容: ${successCount}/${limitedResults.length}`);
}
console.log(`- 结果列表: bing_search_results/Bing搜索_${searchQuery}_${today}_${timeStr}.json`);
if (fetchContent) {
console.log(`- 详细内容: bing_search_results/${searchQuery.replace(/[\\/:*?"<>|]/g, '_')}/${today}/`);
}
} catch (err) {
console.error('程序执行出错:', err);
process.exit(1);
}
}
// 运行主函数
main().catch(console.error);
执行步骤和一些截图
deepseek提示词修改代码
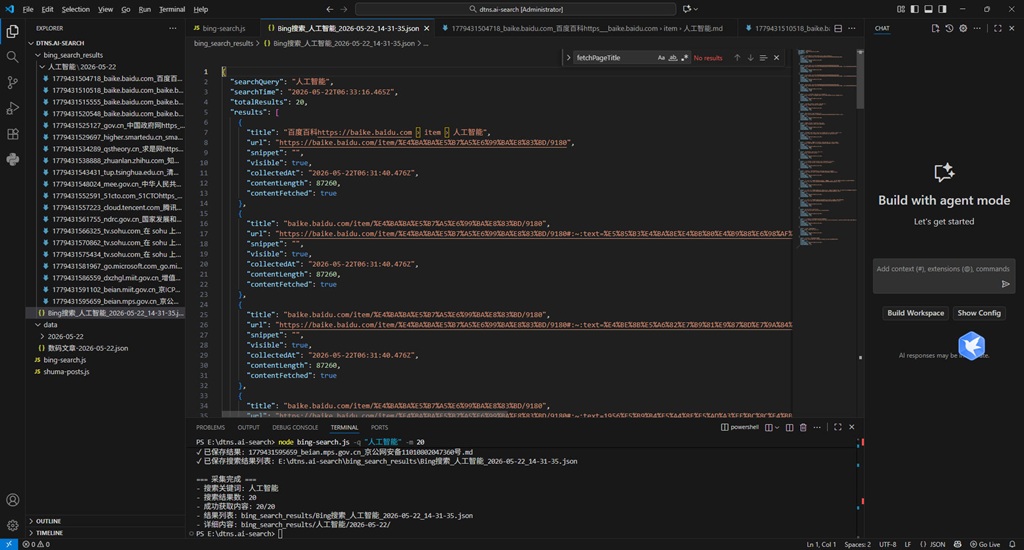
nodejs代码执行的命令
node bing-search.js -q "人工智能" -m 20
基于的命令行参考:
# 基本用法
node bing-search.js --query "搜索关键词"
# 指定最大结果数
node bing-search.js -q "人工智能" -m 20
# 只采集链接,不获取页面内容
node bing-search.js --query "Node.js" --no-content
# 查看帮助
node bing-search.js --help
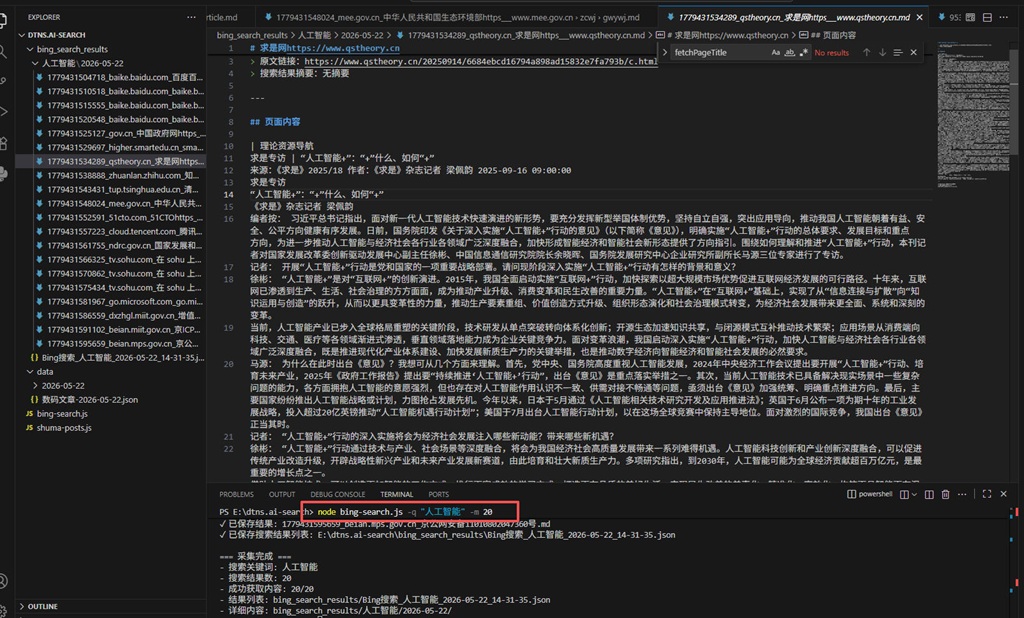
自动化获取搜索结果并打开相应的结果页面
得到的下载结果
附录
AI灵驹(浏览器插件)
开源网址:
https://gitee.com/dtnsman/dtns.ai-pet-pony/tree/master/browser-plugin